C’est quoi un dictionnaire en Python ? Il y a plusieurs types de variables, dont les dictionnaires. Nous n’allons pas voir tout ce qu’il est possible de faire avec un dictionnaire, mais nous allons, à travers un exemple concret, voir comment manipuler un tel type de variables.
Introduction au dictionnaire Python
Un dictionnaire peut être déclaré de deux façons en Python:
my_dico = dict()
# ou
my_dico = {}
Ce type de variable sert à construire une sorte de collection de connexions. D’ailleurs, le mot dictionnaire (« dico » pour les intimes) est explicite. Dans un dico, à chaque mot est associée une définition. C’est la même logique en informatique : à chaque objet inséré dans le dico (ce peut être un chaîne de caractères, un nombre, un booléen, …) est associé un autre objet (non nécessairement du même type). Par exemple on peut définir le dictionnaire suivant:
dico = { 'toto' : 'tata' , 'titi' : 4 , 35.5 : True}
dans lequel on associe:
- ‘tata’ (de type string) à ‘toto’ (de type string);
- 4 (de type int) à ‘titi’ (de type string);
- True (de type bool) à 35 (de type float).
On peut donc associer n’importe quoi à n’importe quoi, à l’instar d’une liste où l’on peut insérer n’importe quel type de variables. Dans cet exemple,
- ‘toto’, ‘titi’ et 35.5 sont des clés (key en anglais);
- ‘tata’, 4 et True sont les valeurs associées aux clés.
Pour avoir accès aux valeurs d’une clé, on tapera:
dico[<clé>]
Pour parcourir un dictionnaire python et afficher toutes ses clés, on écrira par exemple:
for key in dico:
print(key)
qui retourne dans notre cas:
toto titi 35.5
Pour afficher les clés et les valeurs, on pourra écrire:
for key in dico:
print('{} : {}'.format(key,dico[key]))
ou encore:
for key, value in dico.items():
print('{} : {}'.format(key,value))
qui affichent:
toto : tata titi : 4 35.5 : True
Application
Nous allons partir d’un fichier texte contenant un poème de Paul Verlaine, Ariette III :
Il pleure dans mon cœur
Comme il pleut sur la ville;
Quelle est cette langueur
Qui pénètre mon cœur ?
Ô bruit doux de la pluie
Par terre et sur les toits!
Pour un cœur qui s’ennuie,
Ô le chant de la pluie!
Il pleure sans raison
Dans ce cœur qui s’écœure.
Quoi ! nulle trahison ?…
Ce deuil est sans raison.
C’est bien la pire peine
De ne savoir pourquoi
Sans amour et sans haine
Mon cœur a tant de peine!
Mon objectif est de compter les mots de ce fichier, en excluant les ponctuations et en ne retenant que ce qui suit une apostrophe (donc « C’est » sera compté pour « est »). Ensuite, je souhaite construire un diagramme en barres montrant le nombre d’occurrences des mots qui se répètent au moins deux fois.
Une fonction qui élimine les signes de ponctuation
Avant tout, je dois créer une fonction qui élimine le superflu :
list_of_ponct = [ '.' , ';' , '!' , '?' , ',' , ':' , '\n' ]
def del_ponct(mot):
for letter in mot:
if letter in list_of_ponct:
mot = mot.replace(letter,'')
return mot
Je définis une liste dans laquelle je mets tous les signes que je veux exclure. Ne pas oublier le « \n » (retour à la ligne dans un fichier texte).
La logique de ma fonction est la suivante : je parcours le mot mis en argument (avec la boucle for letter in mot) et je teste les lettres pour savoir si elles sont dans ma « liste noire » (if letter in list_of_ponct), auquel cas je la remplace par le vide (comme dans le cerveau du 45ème président des États-Unis d’Amérique). Une fois sorti de la boucle, donc une fois toutes les lettres du mot scannées, je retourne le mot obtenu.
Construction du dictionnaire Python
Je souhaite construire un dictionnaire ayant pour clés tous les mots du fichier et pour valeurs, leurs occurrences.
with open('poeme.txt' , encoding = 'utf8') as f:
for line in f:
words_in_line = line.split(' ')
for word in words_in_line:
word = del_ponct( word )
if "'" in word:
i = word.index("'")
word = word[i+1:]
if word != '':
if word in mots:
counter = mots[word] + 1
mots[word] = counter
else:
mots[word] = 1
J’ouvre le fichier en mode lecture avec la fonction open. La ligne 1 signifie que le fichier que j’ouvre est désigné par la lettre f (pour une syntaxe plus légère).
Ensuite (ligne 2), je boucle sur ce fichier de ligne en ligne. La ligne 3 convertit la ligne courante en une liste de mots (la méthode split appliquée à une chaîne de caractères découpe celle-ci en fonction du caractère informé en argument : ici, on découpe suivant les espaces).
Ensuite (ligne 4), je boucle sur la liste dernièrement créée; j’enlève les ponctuations (ligne 5) et si une apostrophe se trouve dans le mot, je ne prends que ce qu’il y a après l’apostrophe (lignes 6 à 8). La méthode index permet d’avoir la position de la chaîne passée en argument.
Si après ça le mot n’est pas vide, je l’ajoute au dictionnaire (s’il n’y est pas déjà) en lui attribuant une valeur de 1, sinon j’incrémente sa valeur de 1 (lignes 9 à 14).
Suppression des clés à valeurs égales à 1
Les mots qui n’apparaissent qu’une seul fois ne m’intéresse pas. Je vais donc créer une fonction qui les supprime:
def suppr_key(dico , n = 1):
new_dico = dict(dico)
for key,value in dico.items():
if value <= n:
del new_dico[key]
return new_dico
Notez que j’ai créé une fonction admettant en arguments un dictionnaire et un nombre qui, par défaut, est égal à deux, mais qui peut varier selon nos besoins.
La ligne 2 copie le dictionnaire duquel je souhaite ôter des entrées. Je ne peux pas agir directement sur le dictionnaire original car je boucle dessus.
Création d’un histogramme à partir du dictionnaire Python
Pour cela, je vais avoir besoin de matplotlib.pyplot et de ses fonctions bar, show et xticks.
from matplotlib.pyplot import bar,show,xticks
def create_histo(dico):
xticks(rotation = 'vertical')
bar(list(dico.keys()), dico.values(), color='g')
show()
Le programme complet
from matplotlib.pyplot import bar,show,xticks
list_of_ponct = [ '.' , ';' , '!' , '?' , ',' , ':' , '\n' ]
def del_ponct(mot):
for letter in mot:
if letter in list_of_ponct:
mot = mot.replace(letter,'')
return mot
def create_dico(file):
mots = dict()
with open(file , encoding = 'utf8') as f:
for line in f:
words_in_line = line.split(' ')
for word in words_in_line:
word = del_ponct( word )
if "'" in word:
i = word.index("'")
word = word[i+1:]
if word != '':
if word in mots:
counter = mots[word] + 1
mots[word] = counter
else:
mots[word] = 1
return mots
def suppr_key(dico , n = 1):
new_dico = dict(dico)
for key,value in dico.items():
if value <= n:
del new_dico[key]
return new_dico
def create_histo(dico):
xticks(rotation = 'vertical')
bar(list(dico.keys()), dico.values(), color='g')
show()
mots = suppr_key(create_dico('poeme.txt'))
create_histo(mots)
J’ai ici décomposé en plusieurs fonctions afin de rendre le code plus clair.
Cela affiche:
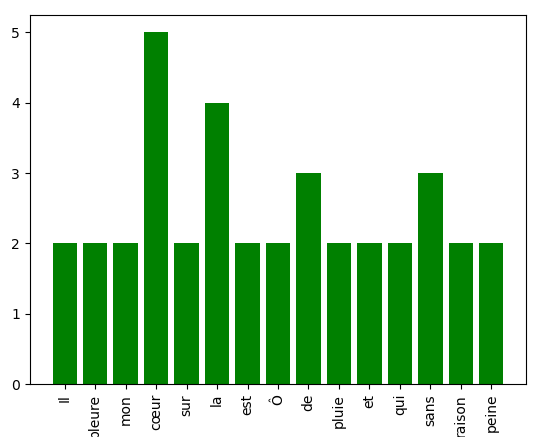
De cette analyse, on constate que le mot « cœur » apparaît 5 fois, ce qui laisse à penser que l’auteur souhaite véhiculer une idée sur le cœur à travers ce poème. Et si on exclut les mots sans intérêt (« la », « et », « qui », …) on s’aperçoit que « peine », « pleure » et « pluie » reviennent deux fois. Ce poème parle donc d’une peine de cœur.
En effet, Verlaine a écrit ce poème sous les toits de Paris, un soir de pluie, après sa douloureuse rupture avec Arthur Rimbaud (me semble-t-il… mais si je me trompe, dites-le moi !).