Calculer la fréquence des lettres dans la langue française avec Python peut s’avérer compliqué si on ne sait pas par où commencer.
Nous allons voir dans cet article comment procéder à partir d’un fichier texte contenant tous les mots de la langue française.
Calculer la fréquence des lettres dans la langue française avec Python: le fichier
Je suis parti du fichier téléchargeable sur le site https://www.freelang.com/dictionnaire/dic-francais.php, en le modifiant un peu (car il y avait quelques anomalies).
Une fois le fichier téléchargé et épuré, l’objectif est de le lire et de compter toutes les occurrences des lettres en stockant les résultats dans un dictionnaire.
Pour cela, il faut faire attention à:
- supprimer les « \n » en fin de lignes;
- supprimer les espaces;
- transformer les caractères accentués en caractères non accentués (en utilisant par exemple le module unidecode et sa fonction éponyme);
- transformer les minuscules en majuscules
Le programme Python
Afin de mieux visualiser les résultats, j’ai opté pour la construction d’un histogramme:
Le programme Python, joint avec le fichiers texte, est disponible pour les abonné·e·s de mathweb.fr ci-dessous :
Résultats
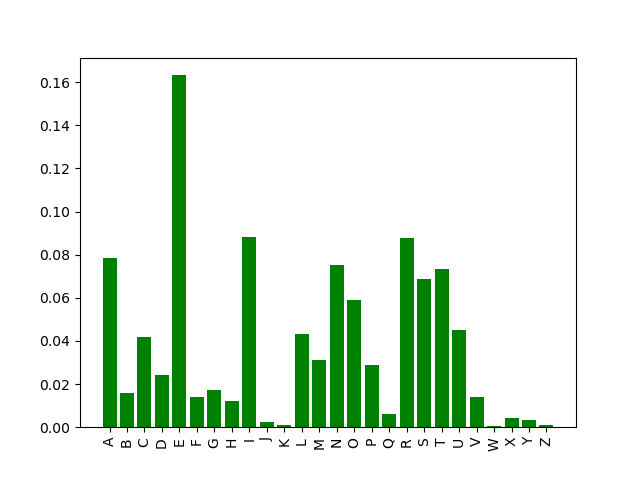
Le programme Python donne alors les fréquences suivantes:
A : 7.87% B : 1.56% C : 4.18% D : 2.41% E : 16.32% F : 1.4% G : 1.72% H : 1.22% I : 8.82% J : 0.24% K : 0.11% L : 4.32% M : 3.1% N : 7.51% O : 5.92% P : 2.89% Q : 0.62% R : 8.78% S : 6.85% T : 7.36% U : 4.5% V : 1.39% W : 0.04% X : 0.43% Y : 0.34% Z : 0.1%
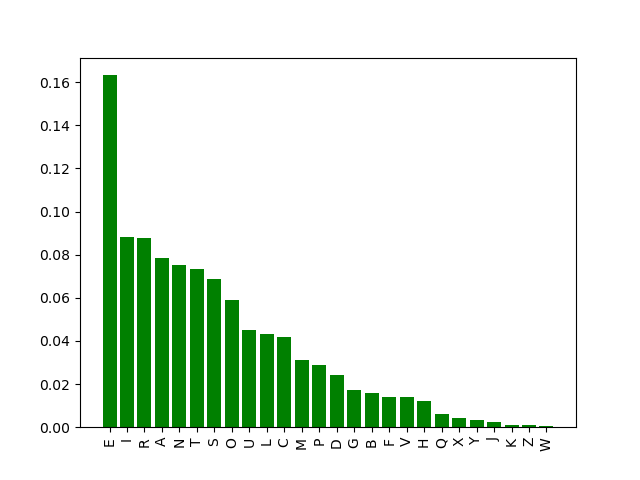
Et quand on demande au programme de trier dans l’ordre décroissant, cela donne:
for c in sorted(alphabet.items() , key = lambda t: t[1] , reverse = True):
frequences[c[0]] = alphabet[c[0]] / nb_lettres
for key,values in frequences.items():
print('{} : {}%'.format(key,round(values*100,2)))
E : 16.32% I : 8.82% R : 8.78% A : 7.87% N : 7.51% T : 7.36% S : 6.85% O : 5.92% U : 4.5% L : 4.32% C : 4.18% M : 3.1% P : 2.89% D : 2.41% G : 1.72% B : 1.56% F : 1.4% V : 1.39% H : 1.22% Q : 0.62% X : 0.43% Y : 0.34% J : 0.24% K : 0.11% Z : 0.1% W : 0.04%
Calculer la fréquence des lettres dans la langue française avec Python: à quoi cela peut servir?
Certaines techniques de cryptographie s’appuient sur les fréquences des lettres dans le langage considéré pour décoder un message.
Cela est valable si le système de codage est bien entendu indépendant de la position des lettres dans le message (par exemple, si le système de codage transforme toujours le « A » en « T »). Mais n’étant pas du tout un spécialiste de la cryptographie, je ne peux en dire davantage.
La seule chose que je peux dire c’est que ce genre de système de codage n’est pas du tout optimal. En effet, on peut deviner à l’aide des fréquences les diverses substitutions. Avec un tel système, le mot « abracadabra » serait transformé par exemple en « kxNkBkOkxNk » (j’ai ici utilisé un chiffrement affine). On voit alors que la lettre « k » apparaît souvent (sa fréquence d’apparition est élevée par rapport à celle des autres lettres), donc elle doit représenter une des premières lettres (« E », « I », « R », « A »).
Cela dit, cette logique ne fonctionne pas pour « hurluberlu » (que j’ai chiffré en « VBPrBxjPrB » avec un chiffrement affine). Mais le « U » apparaît tout de même parmi les premières lettres (9ème position sur 26).
À l’aide des fréquences, on peut donc craquer le code et déchiffrer le message. C’est aussi la raison pour laquelle les chiffrements de ce type ne sont pas utilisés si l’on souhaite assurer une sécurité optimale au chiffrement.


